
Bytewax v0.18 - Elevating Stream Processing to New Heights 🧗♀️ 🧗♂️
Complex DAG Dataflows with Joins & Multiple IO, Enhanced Kafka & Redpanda Integration, Autocomplete & Type Checking and more!


We're thrilled to announce the release of Bytewax v0.18, marking a significant step forward in capabilities. This update brings a lot of new features, optimizations, and changes that cater to the evolving needs of data engineers and developers.
Complex DAG Dataflows with Joins and Multiple IO
One of the most exciting features of v0.18 is that dataflows can now be arbitrary directed acyclic graphs: Your dataflows can include multiple input sources, process each of these streams in isolation, join and merge streams together, branch off error messages and special message types, and include multiple output sinks anywhere in the dataflow. This development allows you to build more complex data processing pipelines that can better match any algorithms and analysis you want to do. Operators are now added on specific individual streams of data and return handles to multiple distinct data streams that can be specifically used later.
See examples in our documentation:
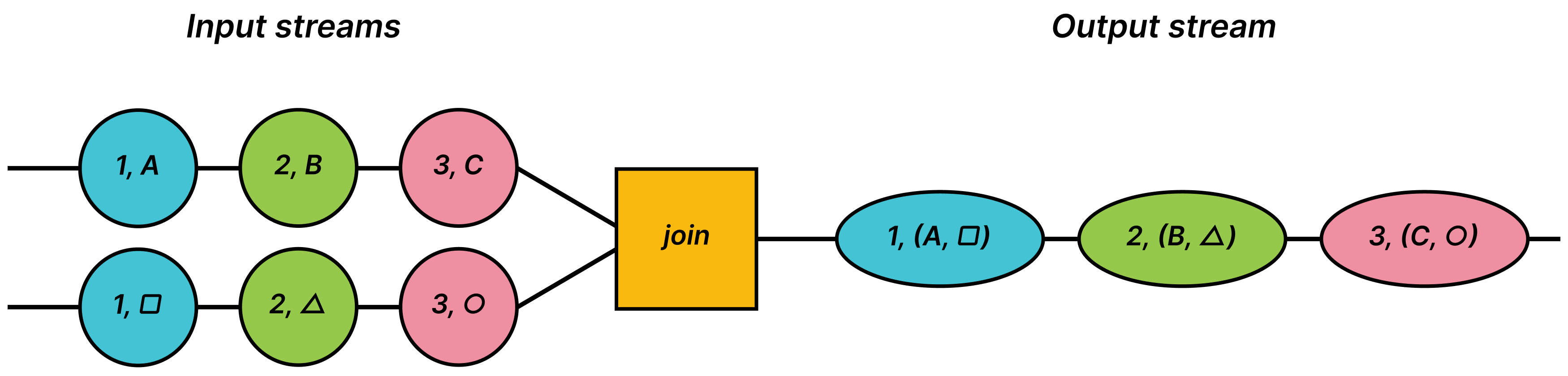
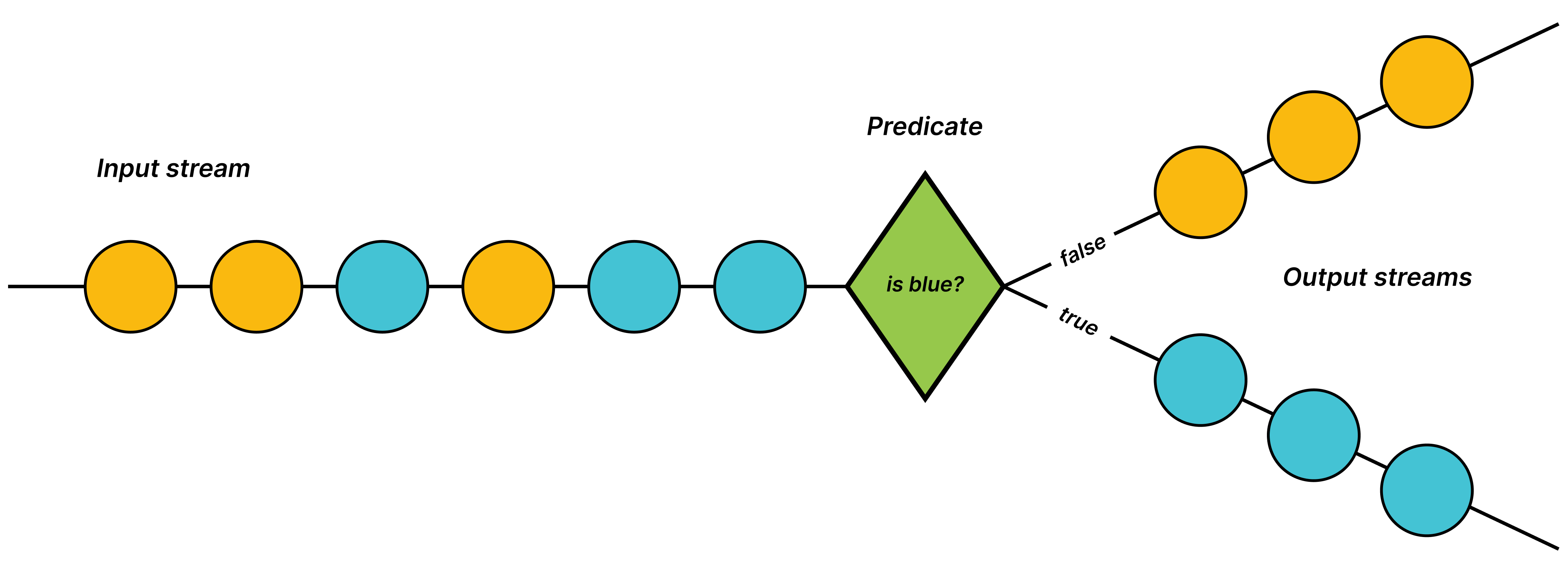
Enhanced Kafka & Redpanda Integration
Bytewax v0.18 introduces advanced support for Kafka and Redpanda, integrating schema registries with the addition of RedpandaSchemaRegistry and ConfluentSchemaRegistry. This release also debuts custom Kafka operators like input, output, deserialize_key, and more, offering greater flexibility and control over Kafka streams.
Autocomplete and Type Checking
Bytewax is now fully type annotated, allowing your language server to provide in-editor hints and errors. See what types are flowing within each stream section, catch issues with signatures and return types in logic functions, know what operators are valid on keyed vs non-keyed streams, etc. We strongly encourage you to add type hints to your logic functions to fully realize this feature.
New Operators
You can now create new operators in Python by grouping existing operators. This allows you to package sets of operators that encode your common reusable logic you want to share among multiple dataflows or with your colleagues. You can store your custom operators in your own Python package if you desire. Read more about the custom operator API here.
For very advanced operations, we also have exposed lower-level operators to give you the full power of Bytewax from Python. The unary and flat_map_batch operators give you access lower level parts of the runtime like: timeouts, snapshotting, and batching.
Important Breaking Changes & Migration Guide Highlights
It's crucial to note several breaking changes in this release. Transitioning to v0.18 is made easier with our detailed migration guide. Here are some key points:
Dataflow Construction API: To support arbitrary DAG dataflows, the custom operator API, and autocomplete, steps are now added to a dataflow via stand-alone operator functions. Their arguments and behavior are unchanged.
Kafka/Redpanda Message Classes:
KafkaSourcenow emits a stream ofKafkaSourceMessagedataclasses to give access to all properties of the message. Update your downstream steps to use the appropriate fields.SimplePollingSourceMove: Update your imports asSimplePollingSourcehas moved frombytewax.connectors.periodictobytewax.inputs.
In Conclusion
Bytewax v0.18 is not just an update; it's a transformation that empowers you to build more robust, efficient, and complex data processing solutions. With its enhanced Kafka support, the introduction of non-linear dataflows, new operators, and improved developer experience, we think Bytewax continues to be a great choice for data engineers and developers working with streaming data. 💛
For a more detailed breakdown of all the changes and new features, make sure to check the release notes and the comprehensive migration guide. Happy data processing!
If you want support migrating, head over to slack or contact us directly.
🐝 🐝 🐝