
Bytewax's MAD Map for Real-time Python Builders
Discover Python's Secret Weapons for Next-Gen Data Handling! 🔥

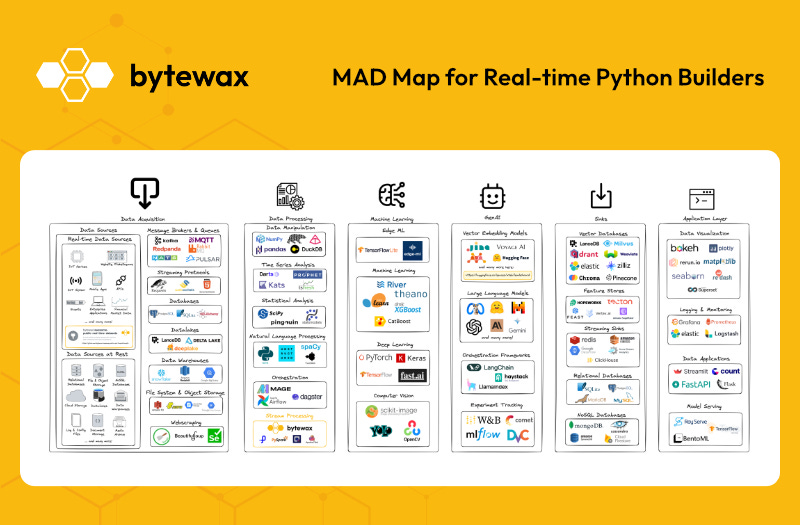
Why we built the Bytewax MAD Map
One of Bytewax's biggest draws is its seamless integration with the Python ecosystem. However, we struggled to find a comprehensive overview of libraries and tools relevant to real-time Python developers. While there are excellent overviews of the data landscape, such as Matt Turck's MAD Landscape and Yujian Tang's monthly updated LLM App Stack, these resources don't specifically address the needs of Python developers working with real-time data. This gap led us down the rabbit hole to create our own MAD (Machine Learning, AI, Data) Map.
Originally, the Bytewax MAD Map began as a slide presentation listing about 20 Python libraries. After sharing this initial list on LinkedIn, the community's response was overwhelmingly positive, leading to the expansion of the list with more tools. Thanks to continuous community feedback, further research, and the efforts of the Bytewax team, the MAD map has now grown to include over 100 tools.
Introduction
The idea of the Bytewax MAD Map for Real-time Python Builders is to give an overview of Python libraries and other tools that can be used alongside Bytewax for real-time IoT, Machine Learning, and GenAI use cases. Rather than attempting to cover every tool available, we focused on the libraries and tools our developers most frequently use. You might notice a preference for open-source tools; this is intentional and reflects the values of our developer community.
Data Acquisition
Data Sources
Data sources are the origin points from which data is collected. They can be divided into real-time sources, which provide immediate data streams, and at-rest sources, which store historical data. Both types of sources can be combined to build comprehensive real-time applications.
Real-time Data Sources
Real-time data sources provide immediate data streams, which are crucial for applications requiring up-to-the-second information.
Examples of real-time data sources are:
IoT Devices
IoT Sensors
Website Clickstreams
Mobile Apps
APIs
Events
Enterprise Applications
Financial Market Data ... and of course, there are many more!
At Bytwax, we maintain a list of awesome public real-time datasets and sources, which can be found here: GitHub Repo
Data Sources at Rest
Data sources at rest include various storage solutions that hold data that can be queried and processed as needed. These sources can store historical data, which is essential for comprehensive analytics and often provides the necessary context for streaming data.
Examples of data sources at rest:
Relational Databases
Files & Object Storage
NoSQL Databases
Cloud Storage
Datalakes
Data Warehouses
Document Storage
Media Archives
Log & Config Files
Message Brokers & Queues
Message brokers and queues are systems that facilitate the reliable transfer of data between applications, ensuring consistent and orderly data delivery.
Streaming Protocols
Streaming protocols are frameworks that enable continuous data streams with low latency, allowing for real-time data transfer.
Requests → GitHub Repo
Server-Sent Events - A server push technology that allows servers to send real-time updates to the client over a single HTTP connection, ideal for live notifications and updates.
Databases
Databases are foundational systems for storing and querying data efficiently, supporting structured data storage and complex queries.
Datalakes
Datalakes provide scalable storage for large datasets, allowing raw data to be stored in its native format and processed as needed.
Data Warehouses
Data warehouses offer optimized storage for structured data and support complex queries, providing powerful analytics capabilities.
File System & Object Storage
File systems and object storage solutions store unstructured data and provide versatile storage and retrieval capabilities.
Amazon S3 - An object storage service offering scalable, high-availability storage with comprehensive security and compliance capabilities.
Azure Blob Storage - A Microsoft cloud-based object storage solution optimized for storing massive amounts of unstructured data, with seamless integration into the Azure ecosystem.
Webscraping
Webscraping tools enable data extraction from web sources, gathering information from websites for processing and analysis.
Data Processing
Data Manipulation
Data manipulation libraries provide tools for cleaning, transforming, and validating data, ensuring it is in the correct format and structure for analysis.
Time Series Analysis
Time series analysis tools are used for forecasting and analyzing trends in time-dependent data, providing insights into patterns and future trends.
Statistical Analysis
Statistical analysis tools offer advanced statistical functions for complex data analysis, supporting a wide range of statistical tests and models.
Natural Language Processing
Natural Language Processing (NLP) libraries facilitate text analysis and processing, enabling applications to understand and interpret language data.
Orchestration
Orchestration tools manage and schedule complex workflows, ensuring that tasks are executed in the correct order and at the right time.
Stream Processing
Stream processing frameworks handle continuous data streams, enabling real-time data processing and analytics at scale. Unlike traditional batch processing, which processes data in large, static chunks, stream processing deals with data as it arrives, allowing for immediate insights and actions.
Machine Learning
Edge ML
Edge ML tools enable machine learning on edge devices, allowing for real-time data processing and analytics at the source.
Machine Learning
Machine learning libraries provide algorithms for data analysis and prediction, which is essential for building and deploying machine learning models.
Deep Learning
Deep learning frameworks enable the development of advanced neural networks for complex tasks such as image recognition and natural language processing.
Computer Vision
Computer vision libraries facilitate image and video analysis, enabling applications to interpret and process visual data.
GenAI
Vector Embedding Models
Vector embedding models offer pre-trained models for various NLP tasks, converting text into numerical vectors for analysis.
The go-to resource for Vector Embedding Models is the Hugging Face's MTEB Leaderboard, which showcases the performance of various models on the Massive Text Embedding Benchmark (MTEB).
Large Language Models
Large language models provide powerful text generation and understanding capabilities, performing tasks such as summarization and conversation generation.
Choosing the right large language model depends on the specific requirements of your use case. This is a very dynamic space, so it is best to use the various performance leaderboards such as the LLM Leaderboard or the Hugging Face Open LLM Leaderboard for selecting an LLM.
Orchestration Frameworks
Orchestration frameworks help in building complex workflows involving multiple AI models and data sources, managing interactions between components.
Experiment Tracking
Experiment tracking tools track, compare, and manage machine learning experiments, keeping track of model versions, parameters, and performance metrics.
Sinks
Vector Databases
Vector databases are optimized for storing and querying high-dimensional data, enabling efficient similarity searches and other vector operations.
A good comparison of the different vector databases on the market can be found on Superlinked's Vector Database Comparison.
Feature Stores
Feature stores manage and serve machine learning features, providing a centralized repository for feature data.
Streaming Sinks
Streaming sinks enable real-time data storage and retrieval, allowing for immediate access to processed data.
Relational Databases
Relational databases provide structured data storage and querying capabilities, supporting complex queries and data analysis.
NoSQL Databases
NoSQL databases offer flexible data models, enabling efficient unstructured and semi-structured data handling.
Application Layer
Data Visualization
Data visualization libraries enable the creation of interactive charts and dashboards, allowing for effective visualization of data insights.
Logging & Monitoring
Logging and monitoring tools provide capabilities for tracking, monitoring, and alerting, ensuring the performance and reliability of applications.
Data Applications
Frameworks for data applications enable the development of interactive data-driven applications, facilitating the deployment of real-time data solutions.
Model Serving
Model serving tools facilitate the deployment and serving of machine learning models, enabling real-time inference and predictions.
🤔 Which of your favorite Python tools are we missing? Let us know which logo you would like to see on our MAD Map.
 | A guest post by
|
Thank you for the Zilliz and Milvus mention!